
Designing with assumptions using a hypothesis-driven approach to service design in complex systems


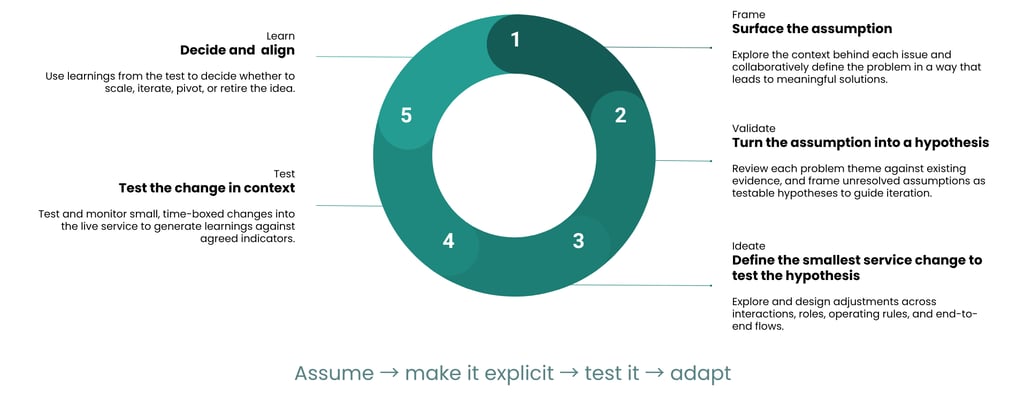
At its core, this approach mirrors a loop rather than a straight line. Each phase builds on the last, but more importantly, each one is designed to reduce uncertainty in a structured way. What makes it work in practice is that every phase has a clear purpose, a set of activities, and tangible outputs that help teams move forward with confidence.
1. Framing: This is where teams attempt to understand the problem properly and make any assumptions visible.
Typical activities:
Cross-disciplinary framing workshops (policy, ops, design, research, analysis)
Mapping where issues show up across the service journey
Identifying affected users and edge cases
Capturing assumptions about what might be happening and why
Outputs:
Clearly defined problem statements
A structured list of assumptions
Key questions that need answering
An initial view of available evidence and gaps
2. Validating: Once assumptions are visible, the next step is to make them usable by turning them into testable hypotheses while ensuring a need for further exploration into the problem based on what existing evidence currently exits.
Typical activities:
Reviewing existing data, research, and operational insight
Working with analysts to assess evidence strength
Reframing assumptions into testable hypotheses (e.g. “We believe X is happening because Y, which leads to Z outcome”)
Prioritising which hypotheses to test
Outputs:
A prioritised set of testable hypotheses
Evidence summaries with confidence levels
A clear rationale for what to test first
3. Ideation: Now the focus shifts from understanding to defining the smallest possible change that can test a hypothesis.
Typical activities:
Collaborative design sessions across disciplines
Exploring changes to touchpoints, roles, rules, or journeys
Mapping operational implications with delivery teams
Aligning on feasibility and constraints
Outputs:
Defined intervention(s) tied directly to the hypothesis
Clear description of what will change in the service
Agreement on scope, duration, and boundaries of the test
4. Test: This is where the learning happens by introducing changes into the live service in a controlled, time-boxed way.
Typical activities:
Deploying small changes into the live environment
Monitoring behavioural and operational data
Gathering qualitative feedback where needed
Tracking defined success indicators
Outputs:
Performance data
Observed user and operational responses
Early signals of impact
5. Learn: This is where teams come back together to make sense of what happened and decide what to do next.
Typical activities:
Reviewing test results against hypotheses
Interpreting data with analysts and researchers
Facilitating decision-making sessions with stakeholders
Aligning on next steps based on evidence
Outputs:
A clear decision on whether to scale, iterate, pivot, or retire
Documented learnings and rationale
Inputs into the next iteration of the loop
This phase closes the loop, but it also sets up the next one. Learning isn’t the end, it’s the input for the next round of framing and refinement. Each phase gives teams just enough structure to move forward with confidence, while staying flexible enough to adapt as new evidence emerges.
How assumptions move through the lifecycle
What makes this approach powerful is how it treats assumptions as something to move through a lifecycle, not something to resolve upfront. An assumption starts as a loose belief often based on partial data, experience, or policy intent. Instead of acting on it immediately, the loop forces it to become explicit, shaped into a hypothesis, tested in context, and evaluated against real outcomes. What this does is turn ambiguity into structured learning.
Example: Missed appointments in an outpatient NHS service
Initial assumption:
“Users are missing appointments because they’re not being reminded.”
This may appear as a reasonable assumption. Missed appointments cost the NHS time and money, and reminders feel like an obvious fix. But without testing it, there’s a risk of investing in the wrong solution. Using this approach, rather than begin to design a solution aimed at the assumption, teams would:
Phase 1:
Surface the assumptions by bringing together service designers, NHS operational staff, policy leads, and analysts.
What emerges:
The issue shows up as high no-show rates in specific clinics
It affects patients with varying needs, including those with complex conditions
Touchpoints include appointment letters, SMS reminders, and booking systems
Key assumptions identified:
Patients forget appointments
Existing reminders aren’t reaching users
More frequent reminders would reduce no-shows
Outputs:
A clearly defined problem: missed appointments in specific contexts
A list of assumptions driving current thinking
Key questions: Are reminders the issue, or is something else at play (e.g. timing, accessibility, transport)?
Phase 2:
Turn assumptions into hypotheses by reviewing existing data and what it indicates:
SMS delivery rates are high
Some patients confirm receipt but still don’t attend
Patterns show higher drop-off in certain demographics and appointment types
Hypothesis formed:
“If patients receive a reminder closer to the appointment time, attendance rates will improve.”
Other competing hypotheses might also emerge:
“Patients are unable to attend due to scheduling conflicts, not forgetfulness”
“Appointment details are unclear or difficult to act on”
Outputs:
A prioritised hypothesis to test
Evidence gaps identified (e.g. reasons behind non-attendance)
Step 3:
Define the smallest service change that's testable, requiring minimal time and resource.
Proposed intervention:
Introduce a same-day SMS reminder for a subset of appointments
Include clearer instructions and an easy way to reschedule
Considerations:
Operational feasibility (can clinics handle rescheduling?)
Technical constraints (SMS system capability)
Policy alignment (data use, consent)
Outputs:
A scoped test affecting a small cohort
Clear definition of what’s changing and where
Step 4:
Introduce the change in a controlled way:
Applied to selected clinics or appointment types
Monitored over a defined time period
What’s tracked:
Attendance rates
Rescheduling behaviour
Operational impact (e.g. admin workload)
Outputs:
Real-world data on whether the reminder timing affects attendance
Early signals on unintended consequences
Step 5:
Decide and align together as a team by reviewing the results together.
Possible outcomes:
Attendance improves → scale the approach
No significant change → revisit assumptions
Increased rescheduling but not attendance → refine hypothesis
Key learning:
The issue may not be about reminders alone but may also link to flexibility, clarity, or external factors affecting attendance.
Decision:
Iterate on the approach or test a different hypothesis (e.g. easier rebooking options)
This example shows how a seemingly straightforward assumption can evolve once it’s properly examined. Instead of jumping straight to “send more reminders,” the team uses the loop to understand what’s really happening and respond accordingly, resulting in a more informed decision, grounded in how the service actually works in reality.
Why everything hinges on the framing phase
The framing phase sets the direction for everything that follows. If the problem isn’t properly understood, or if assumptions remain hidden, the rest of the loop simply reinforces the wrong thing more efficiently. There are many reasons why it's important to get this phase right.
It defines what problem you’re actually solving
It surfaces assumptions before they shape solutions
It connects policy intent to service reality
It sets the direction for all downstream activity
Rushing framing creates false alignment and “Obvious” problems go unchallenged
Root causes get overlooked
Exclusion risks increase
To do this well, framing needs structure. Without it, conversations drift, assumptions stay implicit, and alignment becomes surface-level rather than real. A structured approach gives teams a way to slow down just enough to ask the right questions, surface what’s uncertain, and connect different perspectives into a shared understanding. This is where a more deliberate problem framing framework that has assumptions built in becomes essential, not just to define the problem, but to make assumptions visible and usable so they can be tested and learned from as part of the wider design process.
Enabling safe testing in the live service
Testing in live services means there’s no clean separation between design and reality as changes made will affect real people, in real situations, often with little room for error. This approach creates conditions to move forward without exposing users or operations to unnecessary risk.
Time-boxed, reversible changes: Every intervention is designed to be temporary and easy to roll back. If something doesn’t work, it can be stopped quickly without long-term consequences.
Clear success and safety indicators: Before testing begins, teams define what good looks like and what warning signs to watch for. This ensures issues are spotted early and acted on quickly.
Operational alignment before testing: Frontline teams are involved early, ensuring they’re prepared for any changes and can flag risks that may not be visible at a design level.
Continuous monitoring during tests: Data and feedback are reviewed in real time so adjustments can be made if needed.
Built-in governance checkpoints: Regular review points ensure that what’s being tested is understood, agreed, and proportionate, supporting accountability without slowing progress.
Protecting vulnerable users: Tests can be designed to exclude or carefully include sensitive user groups, ensuring no one is disproportionately impacted during early iterations.
Learning before scaling: Nothing is rolled out widely until there’s enough evidence to support it. This ensures that scaling is based on proven outcomes, not intent or assumption.
This shifts risk from being something discovered too late to something actively designed around from the start.
What changes when teams adopt this approach
Instead of pushing for agreement or relying on past experience, teams start to align around learning, evidence, and shared understanding. Adopting this way of working changes how teams think, collaborate, and make decisions.
Better conversations with policy: Policy colleagues are brought into the process of exploring what might work in practice, creating a more constructive relationship between intent and delivery.
More confidence in decision-making: Teams can point to evidence from real-world tests, making it easier to justify changes and move forward with clarity.
Reduced risk of exclusion: By surfacing assumptions early and testing them, teams are more likely to identify where services may not work for certain groups which allows adjustments to be made before issues become embedded at scale.
Shift from opinion to evidence-led iteration: Ideas are treated as hypotheses, and progress is measured by insight gained rather than agreements reached through discussions and other informal ways.
Stronger cross-disciplinary alignment: Policy, operations, design, and analysis work from a shared structure, reducing misinterpretation and ensuring everyone is contributing to the same learning goals.
Greater transparency and accountability: Decisions are easier to trace back to specific hypotheses, tests, and outcomes, creating a clearer narrative for stakeholders and governance forums.
How to start
This starts with a shift in how you see assumptions. Not as something to eliminate, but as something to work with deliberately. When treated as assets, assumptions become the starting point for learning, not a hidden risk. That shift has a direct impact on inclusion and real-world outcomes. It’s what helps teams catch where services may not work for certain groups before these issues scale, and it grounds decisions in how services actually operate, not just how they’re intended to.
Designing in complex systems will always involve assumptions. The difference is whether they stay hidden or become part of how you learn and improve. When teams start working this way, the impact isn’t just better services, but better decisions about who those services work for and why. A step-by-step breakdown of the problem framing framework used here, including templates and facilitation guidance, is covered in - A problem framing framework for challenging assumptions and driving better decisions.
Oftentimes, assumptions quietly shape decisions long before a prototype is built or research is commissioned. They show up in how a policy is interpreted, how eligibility is defined, or how a service flow is structured. These assumptions are often invisible, baked into decisions that feel “obvious” at the time. And when they go unchallenged, they shape who the service works for, and who it leaves behind. This becomes more pronounced when working at pace, translating policy intent into live services with multiple teams involved.
Policy colleagues, operational leads, analysts, and designers are all making sense of the same problem, often under pressure to move quickly and show progress. In such an environment, assumptions can easily harden into direction, reinforced by governance and the need for alignment. The result is a kind of false confidence when in reality the foundations haven’t been tested. What this points to is a need for a shift in mindset: instead of trying to eliminate assumptions, we need to surface them, work with them, and design in a way that makes them visible and testable from the start.
Why assumptions don’t disappear just because we “do user-centred design”
User-centred design doesn’t remove assumptions, it just changes where they sit. Even with strong research practices, we still make calls about what to explore, which users to prioritise, how to interpret behaviour, and what “good” looks like in a service. In public sector design, these assumptions often start upstream in policy intent and flow downstream into design decisions, long before users are engaged. By the time research happens, some of the biggest decisions have already been shaped by what we think we know. So while user-centred design gives us better tools to challenge assumptions, it doesn’t stop them forming in the first place. This leads to user-centred design giving a false sense of security.
Teams may feel confident they’re “doing the right thing” because research is planned or personas exist, but underlying assumptions can still go untested if they’re not made explicit. Without deliberately surfacing them, they remain embedded in problem definitions, success measures, operational guidances, and solution directions. This leads to mistaking some activities or observations for validation and moving forward with decisions that haven’t actually been challenged.
How exclusion often comes from untested decisions
Exclusion comes through a series of small, untested decisions. It might be in the form of a form that assumes digital access, a process that assumes consistent literacy, or a policy that assumes stable circumstances. It may even be informed by a partial view of existing data that doesn’t paint the whole picture. Each of these feels reasonable in isolation, often grounded in experience or what has worked before. And in many teams, this experience sits with stakeholders who have been close to the service for years. But this familiarity can sometimes create a kind of unconscious confidence, where certain solutions feel “tried and true” and don’t need to be questioned. Over time, these assumptions become embedded, shaping decisions without being surfaced or tested.
Because these assumptions stay invisible, they’re hard to challenge. They don’t show up as risks in governance conversations or as clear gaps in delivery plans. Instead, they surface later as drop-offs, complaints, or workarounds in operations. By then, the cost of change is higher and the impact has already been felt. What this points to is a need to shift when and how we deal with exclusion.
Why assumptions are amplified in policy-led services
Policy intent is typically defined at a high level, often shaped by political priorities, legislative constraints, and desired outcomes. But when the intent is translated into a working service, a gap appears between what was envisioned and what can actually be delivered in practice. This gap gets filled with interpretation by policy teams, designers, operational leads, and analysts, each bringing their own perspective on what the service should do and how it should work. With multiple stakeholders involved, each balancing competing priorities like compliance, cost, user need, and delivery timelines, assumptions become the glue that holds decisions together.
At the same time, governance and accountability structures create pressure to show progress and maintain alignment. Decisions need to be justified, risks need to be managed, and delivery needs to keep moving. In such an environment, challenging assumptions can feel like slowing things down or introducing uncertainty at the wrong moment. So instead, assumptions are often left unexamined, reinforced through meetings, sign-offs, and delivery plans.
Why we need to handle assumptions, not avoid them
There’s a common instinct in design to try and eliminate assumptions altogether, often framed as “removing bias” from the process. It’s well-intentioned, but not realistic. Every decision we make from what to prioritise, which users to focus on, or how to interpret evidence involves some level of judgement. In policy-led services, this is even more pronounced. Policy itself is built on assumptions about behaviour, need, and outcomes, and those assumptions don’t disappear when they enter delivery. Trying to strip them out entirely can lead to a false sense of objectivity, where decisions appear neutral but are still shaped by unexamined beliefs. The issue isn’t that assumptions exist, it’s that they often go unnamed and therefore unchallenged.
A more useful shift is to treat assumptions as design opportunities rather than design flaws. They’re signals of uncertainty, gaps in evidence, or areas where different perspectives haven’t yet been reconciled. When surfaced early, they can guide where to focus research, what to test, and how to structure iteration. Instead of trying to design around assumptions, we design through them, using them to drive learning rather than letting them quietly dictate decisions.
Hypothesis-driven iterative service improvement as a solution
Hypothesis-driven iterative service improvement gives teams a shared way to move from assumption to evidence without slowing delivery down. Instead of debating opinions or relying on past experience, it reframes decisions as testable hypotheses that can be explored in the live service. By structuring work around hypotheses, you create a common language that cuts across perspectives. Everyone aligns not on what they think is happening, but on what they’re trying to learn, how they’ll test it, and what evidence will inform the next move.
This approach also works with governance rather than against it. Instead of presenting fixed solutions for approval, teams can bring forward clear assumptions, defined tests, and measurable outcomes. This makes decision-making more transparent and reduces the risk of committing to changes that haven’t been validated. It creates space for collaboration without losing momentum, because progress is tied to learning rather than certainty. Over time, it shifts conversations from defending ideas to evaluating evidence, which is where alignment becomes more durable. Other benefits include:
Reduced reliance on opinion and seniority in decision-making: By framing ideas as hypotheses, decisions are no longer justified by who suggested them or how confident they sound. Instead, they’re evaluated based on what evidence supports or disproves them, creating a more balanced environment for contribution across roles.
Making assumptions visible and easier to challenge: Assumptions are explicitly captured and turned into problem statements or hypotheses. This visibility makes it easier for teams to question them constructively and align on what needs to be tested.
Enabling smaller, safer changes in live services: Instead of large-scale changes based on untested ideas, teams introduce targeted, time-boxed adjustments designed to validate specific hypotheses. This reduces risk while still allowing progress in a live environment.
Preventing duplication of research and testing across teams: With analysts and delivery teams aligned on existing evidence, there’s greater visibility of what’s already been explored. This helps avoid repeating the same tests and ensuring effort is focused where uncertainty and impact is highest.
Strengthening the link between policy intent and service outcomes: Hypotheses often originate from policy assumptions, making it easier to trace how intent is being interpreted and tested in the service. This creates a clearer connection between what policy aims to achieve and what actually happens in operations.
Creating a clear audit trail for decisions and changes: Each problem statement, hypothesis, test, and outcome provides a documented rationale for why changes are made. This is valuable in governance-heavy environments where accountability is critical.
Supporting continuous improvement without large-scale disruption: Because the approach is iterative and incremental, services can evolve over time without the need for major transformation efforts. This makes improvement more sustainable and responsive to changing needs.
The 5-stage design process from assumptions to tested service improvements
Let's chat about your next design project.
Phone
kolawale.design@gmail.com
07826 451774
© 2025. All rights reserved.
Social